The R Consortium had a conversation with Anietie Edem Udokang, who is the founder and organizer of the Offa R Users Group (ORUG). He discussed the emerging local R community and the use of R for his research in time series analysis.
The Offa R Users Group has a Meetup coming up on March 26th, 2024, titled “Test for the Assumptions of Linear Regression Using R.” The group is also seeking individuals to serve as guest speakers for their online events.
Please share about your background and involvement with the RUGS group.
My name is Anietie Edem Udokang, and I am a chief lecturer at the Federal Polytechnic Offa. I hold a Master of Science degree in Statistics. It was during my postgraduate studies that my supervisor introduced me to R, which was around 2012. Since then, I’ve been using R and have discovered that it’s far superior to some of the other software programs I had previously used.
I have found that interacting with others and utilizing specific features, such as the ability to download applications, has been incredibly beneficial to my analysis work. These special packages have helped me greatly, and I believe it is important to attach relevant packages when organizing data. This experience has made me passionate about using R for data analysis.
Ever since I began using R, I have had the privilege of engaging with a diverse group of individuals, including data scientists and software users. These interactions have led me to the realization that to continue growing and learning, it would be beneficial to establish a user group within our community. Initially, we called it the “Fedpofa R Users Group,” but later changed the name to “Offa R Users Group.” We have been organizing meetings, providing training, and engaging in other activities to keep the community vibrant.
Can you share what the R community is like in Offa?
R is not limited to academic use, but it is also used in industry. The reason for this is that polytechnics act as a bridge between the industry and academic institutions. If the students have a good grasp of how to use R, it means that industry will be directly or indirectly affected. Consultants often visit our ORUG and ask for some analysis, which we provide using R. Additionally, students also use R for their projects.
I use R for many of my publications. R has gained a lot of popularity, not only within our institution but also among sister institutions in the area. Some departments have even made R the only software that students are required to use for analysis.
What industry are you currently in? How do you use R in your work?
Some authors use regression models without checking whether the assumptions hold or not. Instead of carrying out tests to confirm this, they assume that the model is valid if the assumptions are fulfilled. This topic aims to highlight the importance of carrying out such tests to ensure reliable and comprehensive results. Lack of adherence to the assumptions may lead to inaccurate conclusions. The focus will be on commonly used tests for normality, linearity, autocorrelation, heteroscedasticity/homoscedasticity, and multicollinearity, with illustrative examples using R.
I appreciate the R Consortium for their valuable RUGs grant assistance in 2022. With this grant, I could open two other user groups: the Ilorin R Users Group and the Kwara Environmental Statistics R Group. I also want to express my gratitude to the R Consortium for sponsoring my Meetup subscription and covering other minor expenses in 2022. The subscription is still ongoing, and I hope that we can continue our partnership to promote the use of R in our community.
I would like to request for speakers to present at our R User Group. We are currently seeking speakers for our upcoming events and would be delighted to welcome speakers from all over the world to share their R-related knowledge with us.
How do I Join?
R Consortium’s R User Group and Small Conference Support Program (RUGS) provides grants to help R groups organize, share information, and support each other worldwide. We have given grants over the past four years, encompassing over 68,000 members in 33 countries. We would like to include you! Cash grants and meetup.com accounts are awarded based on the intended use of the funds and the amount of money available to distribute.
Fernanda Kelly, founder and organizer of the R-Ladies Goiânia, recently talked to the R Consortium about the group’s efforts to provide a learning and networking platform to gender and ethnic minorities in the local R community. She discussed the group’s successful transition to virtual events, which has helped increase its visibility and reach.
Please share about your experience and involvement with the RUGS group.
My name is Fernanda Kelly, and I’m 28 years old. I graduated from the Federal University of Goiás with a degree in statistics. During my studies, I became familiar with the R programming language. However, it wasn’t until 2019 that I realized how underrepresented women and black people are in this field. This led me to establish a new R-Ladies chapter that same year to promote diversity and inclusion in the industry.
I worked as a statistician for 4 years at Hospital Moinhos de Vento, where I was involved in the Pfizer Project that analyzed the effectiveness of the COVID-19 vaccine in Brazil. After that, I worked as a Data Scientist at Accenture Brasil. I hold a degree in Machine Learning and an MBA from the University of São Paulo. Recently, I completed a specialization in project management, and I am currently pursuing a master’s degree in Intelligent Systems and their applications in the Healthcare sector.
I have incorporated the R language extensively in my work and studies. Its versatility in interacting with other languages and its diverse range of tools for creating reports, such as R Markdown and Quarto, provide users with multiple ways to develop high-quality models and reports. I have used R for various tasks, such as modeling, data processing, manipulation, and writing with blogdown and R Markdown. R’s constant updates and information dissemination about its features have increased my usage of the language even more.
I haven’t been involved with the RUGS community lately, but I found out about the initiative on LinkedIn and thought, ‘Why not apply?’ Sometimes we hold ourselves back and don’t even consider applying for opportunities, but I applied this time and succeeded.
Our group is a chapter of the global R-Ladies community that strives to promote awareness of R programming language among individuals belonging to minority genders. We cover a broad range of topics helping facilitate individuals entering the job market. Some topics we cover include public speaking, mentoring on how to fill out LinkedIn, and occasionally Excel. We believe R programming goes beyond just coding and that is why we emphasize the development of soft skills as well. We view the community as a trainer of future professionals. To date, we have held over 40 meetings, and this year we plan to offer over 20 workshops. These workshops will cover an array of diverse topics, but our primary goal is to showcase the functionalities of the R programming language in comparison to other programming languages like Python.
I want to emphasize that the work I have accomplished for the R community since 2019 with R-Ladies Goiânia was not a solo endeavor. I have great admiration for the exceptional women I have walked alongside, and currently, I am fortunate to have Jennifer Lopes (a remarkable black woman) by my side since 2023, who has been helping me with R-Ladies Goiânia.
Can you share what the R community is like in Goiânia?
When I talk about community, I also refer to the city of Goiânia, located in the heart of Brazil, where the population is a mix of different ethnicities. The R community in Goiânia is huge, especially within the university. Many degree programs use R as their primary programming language. I fell in love with the power of the R during my undergraduate studies in statistics. However, during my master’s degree, I realized that there was a lack of representation for minority genders and ethnic groups. This led me to search for communities that catered to this audience. As a result, I discovered the R-Ladies community and founded the R-Ladies Goiânia chapter in mid-May 2019. Since then, the chapter has grown and reached out to many women, black people, and members of the LGBT community.
R language is widely used in Brazil across various sectors, including health, agriculture, and financial institutions. The primary reason for its popularity is the vast range of packages it offers and the structured control offered by CRAN, which enhances the language’s credibility and security.
Do you have an upcoming event planned? Can you share more about the topic covered? Why this topic?
We have an upcoming event planned which will be presented by Julia Helen, who lives in Rio de Janeiro. She is a statistician by profession and works as a data scientist at a large television station in Brazil. The meetup will cover the connection between R and Python. This event will take place on March 16th, and everyone is invited to attend. The primary focus of the meeting will be to teach R programmers how to use Python within RStudio effectively. By leveraging both languages, programmers will take advantage of their combined functionalities. The choice of this topic is because of the high demand among R programmers to learn about the use of Python and how to make both languages work seamlessly within RStudio.
Any techniques you recommend using when planning or during the event? (Github, zoom, other) Can these techniques be used to make your group more inclusive for people who may not be able to attend financial events in the future?
R-Ladies Goiânia is present on diverse networks, but we recommend using GitHub to access our course material. We have complete control over the material available on GitHub, and it helps participants gain knowledge on the platform, which is often required by companies in Brazil. We are currently using Zoom through the Sympla platform, which is free and offers many control options over the event. The platform allows us to manage registration, accept the code of conduct, and send certificates to attendees.
We have hosted our meetings online since 2020, and it has worked well for our group. In our meetings we have people from various states in Brazil and, sometimes, we have people from other countries participating. This is incredible and this way we can reach more people, making the chapter decentralized. We have already reached 100 people watching the Introduction to R meetup. All of our events are recorded, and this gives people who could not attend the live event and people in career transition the opportunity to access the content. Currently, our YouTube channel has more than twenty videos.
For the future, we are planning more accessibility, but we know how poorly developed the accessibility of broadcasting platforms is. R-Ladies Goiânia aims to achieve real diversity in its meetings and has been working towards this with campaigns on Instagram, LinkedIn and Twitter. We are seeking innovation and managed to open a mentoring program, which is a big step for the chapter and we are extremely happy.
Please share about a project you are currently working on or have worked on in the past using the R language. Goal/reason, result, anything interesting, especially related to the industry you work in?
What resources/techniques do/did you use? (Posit (RStudio), Github, Tidyverse, etc.)
In this project, we utilized a range of techniques. R Markdown was the most frequently used tool for generating reports in both HTML and PDF formats. Apart from the tidyverse package, we also employed a variety of packages for analyzing PDF data (such as pdftools), data analysis (including lme4 and sampling), and data tabulation (such as reactable, DT, and qwraps2). We utilized GitHub solely to host the codes for the published article.
How do I Join?
R Consortium’s R User Group and Small Conference Support Program (RUGS) provides grants to help R groups organize, share information, and support each other worldwide. We have given grants over the past four years, encompassing over 68,000 members in 33 countries. We would like to include you! Cash grants and meetup.com accounts are awarded based on the intended use of the funds and the amount of money available to distribute.
Contributed by Charlie Gao, Director at Hibiki AI Limited
{nanonext} is an R binding to the state of the art C messaging library NNG (Nanomsg Next Generation), created as a successor to ZeroMQ. It was originally developed as a fast and reliable messaging interface for use in machine learning pipelines. With implementations readily available in languages including C++, Go, Python, and Rust, it allowed individual modules to be written in the most appropriate language and for them to be piped together in a single workflow.
{mirai} is a package that enables asynchronous evaluation in R, built on top of {nanonext}. It was initially created purely as a demonstration of the reliable RPC (remote procedure call) protocol from {nanonext}. However, open-sourcing this project greatly facilitated its discovery and dissemination, eventually leading to a long-term, cross-industry collaboration with Will Landau, a statistician in the life sciences industry, author of the {targets} package for reproducible pipelines. He ended up creating the {crew} package to extend {mirai} to handle the increasingly complex and demanding high-performance computing needs faced by his users.
As this work was progressing, security was still a missing piece of the puzzle. The NNG library supported integration with Mbed TLS (a SSL/TLS library developed under the Trusted Firmware Project), however secure connections were not yet a part of the R landscape.
The R Consortium, by way of an Infrastructure Steering Committee (ISC) grant, funded the work to implement this functionality from the underlying libraries and to also devise a means of configuring the required certificates in R. The stated intention was to provide a user-friendly interface for doing so. The end result somewhat exceeded these goals, with the default allowing for zero-configuration, single-use certificates to be generated on-the-fly. This affords an unparalleled level of usability, not requiring end users to have any knowledge of the intricacies of TLS.
Will Landau talks about the impact TLS has had on his work:
“I sought to extend {mirai} to a wide variety of computing environments through {crew}, from traditional clusters to Amazon Web Services. The integration of TLS into {nanonext} increases the confidence with which {mirai} can be deployed in these powerful environments, accelerating downstream applications and {targets} pipelines.”
The project to extend {mirai} to high-performance computing environments was featured in a workshop on simulation workflows in the life sciences, given at R/Pharma in October 2023 (video and materials accessible from https://github.com/wlandau/rpharma2023).
With the seed planted in {nanonext}, {mirai} and {crew} have grown to form an elegant and performant foundation for an emerging landscape of asynchronous and parallel programming tools. They already provide new back-ends for {parallel}, {promises}, {plumber}, {targets}, and Shiny, as well as high-level interfaces such as {crew.cluster} for traditional clusters and {crew.aws.batch} for the cloud.
Last year, R Consortium talked to John Blischak and Tim Hoolihan of the Cleveland R User Group about their regular structured and casual virtual meetups during the pandemic. Recently, Alec Wong, another co-organizer of the Cleveland R User Group, updated the R Consortium about how the group provides a networking platform for a small but vibrant local R community. Alec shared details of a recent event from the group regarding the use of R for analyzing baseball data. He also discussed some tools for keeping the group inclusive and improving communication among group members.
Please share about your background and involvement with the RUGS group.
I completed my Bachelor of Science degree in Fisheries and Wildlife from the University of Nebraska-Lincoln in 2013, and my Master of Science degree in Statistical Ecology from Cornell University in late 2018. During my graduate program, I gained extensive experience using R, which is the de facto language of the ecological sciences. I discovered a passion for the language, as it is extremely intuitive and pleasant to work with.
After completing my program in 2018, I moved to Cleveland and immediately began attending the Cleveland R User Group in 2019, and have been a consistent member ever since. I eagerly look forward to each of our events.
After completing my graduate program, I started working at Progressive Insurance. Working for a large organization like Progressive provides me with many diverse opportunities to make use of my extensive experience with R. I was happy to find a vibrant R community within the company, which allowed me to connect with other R users, share knowledge, and I enthusiastically offer one-on-one assistance to analysts from all over Progressive.
Starting in 2022, I accepted the role of co-organizer of the Cleveland R User Group. As a co-organizer, I help with various tasks related to organizing events, such as the one we held last September. I am passionate about fostering the growth of these communities and helping to attract more individuals who enjoy using R.
Our group events are currently being held in a hybrid format. When we manage to find space, we will meet in person, such as when we met to view the 2023 posit::conf in October–several members visited in person and watched and discussed videos from the conference. Most of our meetups continue to be virtual, including our Saturday morning coffee meetups, but we are actively searching for a more permanent physical space to accommodate our regular meetups.
I am only one of several co-organizers of the Cleveland R user group. The other co-organizers include Tim Hoolihan from Centric Consulting, John Blischak who operates his consulting firm JDB Software Consulting, LLC, and Jim Hester, currently a Senior Software Engineer at Netflix. Their contributions are invaluable and the community benefits tremendously from their efforts.
Can you share what the R community is like in Cleveland?
I believe interest in R has been fairly steady over time in Cleveland since 2019. We have a handful of members who attend regularly, and typically each meeting one or two new attendees will introduce themselves.
I would venture to say that R continues to be used frequently in academic settings in Cleveland, though I am unfamiliar with the standards at local universities. At least two of our members belong to local universities and they use R in their curricula.
As for industry usage, many local companies, including Progressive use R. At Progressive, we have a small, but solid R community; although it is not as large as the Python community, I believe that the R community is more vibrant. This seems characteristic of R communities in varying contexts, as far as I’ve seen. Another Cleveland company, the Cleveland Guardians baseball team, makes use of R for data science. In September 2023 we were fortunate to invite one of their principal data scientists to speak to us about their methods and analyses. (More details below.)
Typically, our attendance is local to the greater Cleveland area, but with virtual meetups, we’ve been able to host speakers and attendees from across the country; this was a silver lining of the pandemic. We also hold regular Saturday morning coffee and informal chat sessions, and it’s great to see fresh faces from outside Cleveland joining in.
On September 27th, 2023, we invited Keith Woolner, principal data scientist at the Cleveland Guardians baseball team, to give a presentation to our group. This was our first in-person meetup after the pandemic, and Progressive generously sponsored our event, affording us a large presentation space, food, and A/V support. We entertained a mixed audience from the public as well as Progressive employees.
Keith spoke to us about “How Major League Baseball Teams Use R to Analyze Baseball Data.” In an engaging session, he showcased several statistical methods used in sports analytics, the code used to produce these analyses, and visualizations of the data and statistical methods. Of particular interest to me was his analysis using a generalized additive model (GAM) to evaluate the relative performance of catchers’ ability to “frame” a catch; in other words, their ability to convince the umpire a strike occurred. The presentation held some relevance for everyone, whether they were interested in Cleveland baseball, statistics, or R, making it a terrific option for our first in-person presentation since January 2020. His presentation drove a lot of engagement both during and after the session.
Any techniques you recommend using for planning for or during the event? (Github, zoom, other) Can these techniques be used to make your group more inclusive to people that are unable to attend physical events in the future?
One of our co-organizers, John Blischak, has created a slick website using GitHub Pages to showcase our group and used GitHub issue templates to create a process for speakers to submit talks. Additionally, the Cleveland R User group has posted recordings of our meetups to YouTube since 2017, increasing our visibility and accessibility. Many people at Progressive could not attend our September meetup and asked for the recording of our September 2023 meetup as soon as it was available.
Recently, we have also created a Discord server, a platform similar to Slack. This was suggested by one of our members, Ken Wong, and it has been a great addition to our community. We have been growing the server organically since October of last year by marketing it to attendees who visit our events, particularly on the Saturday morning meetups. This has opened up an additional space for us to collaborate and share content asynchronously. Ken has done an excellent job of organizing the server and has added some automated processes that post from R blogs, journal articles, and tweets from high-profile R users. Overall, we are pleased with our progress and look forward to continuing to improve our initiatives.
How do I Join?
R Consortium’s R User Group and Small Conference Support Program (RUGS) provides grants to help R groups organize, share information, and support each other worldwide. We have given grants over the past four years, encompassing over 68,000 members in 33 countries. We would like to include you! Cash grants and meetup.com accounts are awarded based on the intended use of the funds and the amount of money available to distribute.
Help build R infrastructure! We’re opening the call for proposals for the 2024 Infrastructure Steering Committee (ISC) Grant Program. The R Consortium is dedicated to enriching the R Ecosystem, directly supporting projects that strengthen both its technical and social infrastructures.
Our grants target projects that make a difference in the R community, focusing on:
Technical Infrastructure: Enhancements in key R packages, development tools like R-hub, and improvements for R on various operating systems.
Social Infrastructure: Projects like SatRDays that promote local engagement and initiatives for better tracking of R Consortium activities.
We’re eager to see your innovative ideas and how they can propel the R ecosystem forward. This is a call to action for all who wish to contribute to the growth and enhancement of R. Let’s build a stronger R community together!
Submit your proposal now and be a part of shaping the future of the R Ecosystem. Learn more about how to apply here.
We look forward to your submissions and furthering the R community’s advancement together!
Letter from the Chair — Mehar Pratap Singh, Chairman
Welcome to the 2023 Annual Report of the R Consortium. This document reflects a year of significant growth, innovation, and community engagement within and beyond the R ecosystem. As we present the accomplishments and milestones of the past year, we also set our sights forward, laying out the path for an even more collaborative and impactful future.
The R Consortium serves as a central hub for the R community, bringing together industry leaders, academic institutions, and individual contributors to foster the development and proliferation of the R language. Our mission is to support the R community through funding, infrastructure improvement, community initiatives, and global outreach.
In 2023, the R Consortium played a pivotal role in shaping the development of the R ecosystem. Through monetary grants, nearly $200,000 dollars to develop R packages and other technical infrastructure, through fostering industry wide collaborative working groups, and by supporting R-Ladies, R user groups, and several important industry conferences, including Latin-R, New York R, and Bioconductor conferences. This report highlights some of these achievements, showcasing the collective effort of our members and the broader community.
Recognizing the dynamic nature of data science technologies and the evolving needs of industry, we also recognize the responsibility of the R Consortium to help set a vision for the evolution of the R ecosystem. As you read through this report, we hope you’ll appreciate the strides we’ve made together and feel inspired by the potential of what we can achieve in the future. The R Consortium is more than just an organization: it’s a vibrant community of innovators, problem-solvers, and thought leaders. Together, we are shaping a future where the power of R is accessible to all and continues to drive progress across industries worldwide.
Thank you for your continued support and dedication to the R Consortium and the wider R community.
The R Consortium recently reconnected with Paul Stewart, founder of Moffitt Cancer Center Bio-Data Club in Tampa, Florida. Since the last update on January 6th, 2023, the Moffitt Cancer Center Bio-Data Club has hosted special guest Dr. Josh Starmer of StatQuest, and it has welcomed new co-organizers Rodrigo Carvajal, Nathan Van Bibber and Dr. Alex Soupir. The club has maintained its momentum with monthly meetings that have featured enriching discussions, educational talks, and practical tutorials.
One big change they have made this year is revamping their annual hackathon to broaden its scope and encourage greater participation from external academic institutions and industry partners. This expansion aims to enrich the event with diverse perspectives and innovative ideas, marking a significant step forward for the club and its contributions to bioinformatics and cancer research.
What is new with Moffitt Cancer Center Bio-Data Club since last we spoke on Jan 6th, 2023?
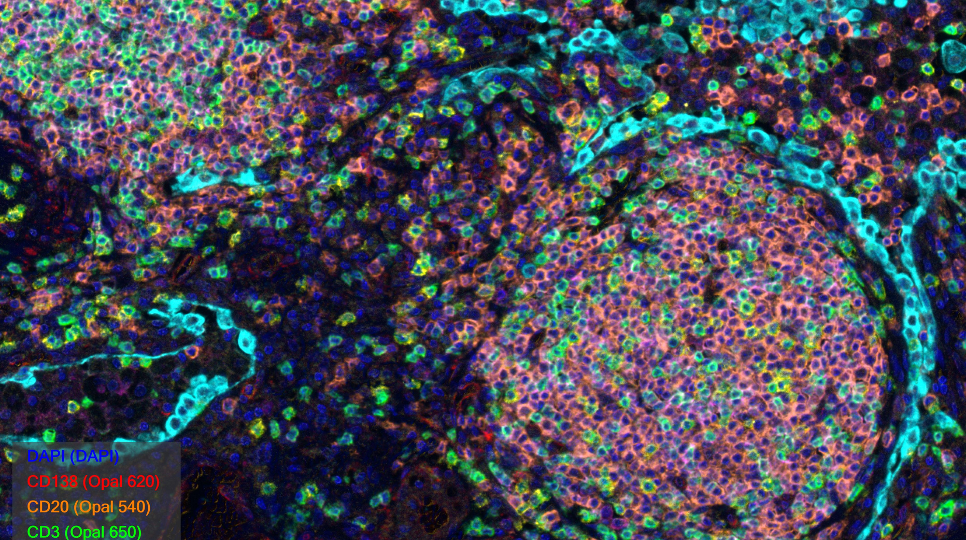
Something new is that we hosted sessions on spatial data analysis. Our work at Moffitt often involves big molecular data, delving into patients’ tumor samples or blood to uncover insights about genes, proteins, and metabolites. This exploration aims to unravel the intricacies of cancer, paving the way for new treatments or early detection methods. Traditionally, we analyze patient tumors in bulk, meaning the entire sample is processed at once, and molecules of interest are extracted and profiled. However, the resulting data are just numbers in a matrix, and we lack the ability to define what part of the tumor the numbers are coming from. New spatial technologies have recently revolutionized our understanding of cancer and other diseases. We can now spatially resolve where genes, proteins, and metabolites come from in the tumor and neighboring cells. This advancement adds a crucial spatial dimension to our research, necessitating novel methods for data processing, quality control, and interpretation. Not to mention, these approaches generate some cool pictures. For example, here is an image from a spatial assay run at Moffitt for a project that I lead (funded by the Cancer Research Institute):
I also want to touch on our hackathon. We’ve decided to broaden its scope this year, extending an open invitation to foster greater participation. Previously, attendance was mainly limited to the Bio-Data Club Meetup and our immediate connections at Moffitt. This year, we’re reaching out more actively to other academic institutions like the University of South Florida and industry partners. We are hoping to increase participation beyond last year’s 50 participants, and we are hoping to enrich the event with diverse perspectives and innovative ideas.
Please share about your background and your involvement in the R Community.What is your level of experience with the R language?
I helped initiate the Bio-Data Club at Moffitt back in 2018. It began as an internal group but soon gained interest from beyond Moffitt, leading us to secure funding from the R Consortium. Since then, I’ve been dedicated to leading the club. In addition to this, I mentor trainees at Moffitt, including Moffitt research staff and students from the University of South Florida.
I’m actively engaged in the local data science community; I’ve delivered lectures at the Tampa Bay R Users Group, the Tampa Bay Data Science Meetup, and, notably, at the 2023 D4CON Data Science Conference in Tampa, organized by Lander Analytics. (Editor’s note: Lander Analytics is an R Consortium member.) While my talks aren’t exclusively about the R programming language, they are intended to cater to the Tampa data science community.
My experience with R spans over a decade. As a Moffitt Cancer Center faculty member, I extensively leverage R in my research. I’d classify my proficiency as advanced, though I wouldn’t label myself an expert because I still learn new things about this great language daily.
Why do industry professionals come to your user group? What is the benefit of attending?
Being a part of Moffitt, located on the University of South Florida campus, our focus naturally gravitates toward biomedical academic research, and showcasing how data science operates within an academic research setting is beneficial. It offers a unique perspective and exposes attendees to cutting-edge techniques, like spatial omics analyses, which might not be part of the typical workload in a standard 9-to-5 job. However, our meetings must cater to a broad audience. Our meeting topics are applicable across many interests, one of which comes to mind was a presentation and demo by ComplexHeatmap author Dr. Zuguang Gu. We’re committed to broadening our discussions and introducing various topics and libraries relevant to R users and the broader data science community. My aim is to ensure that our meetings are inclusive, informative, and beneficial for everyone involved, irrespective of their field of work.
What trends do you currently see in R language and your industry? Any trends you see developing in the near future?
The realm of spatial omics and spatial data analysis, especially in the context of big biological data like genomics, proteomics, and metabolomics, is rapidly evolving. It’s fascinating to see the development of numerous packages, including spatialGE and scSpatialSIM, which are pioneered right here at Moffitt. These tools are a game-changer because they allow individuals who aren’t necessarily experts in imaging or spatial data analysis to engage in and benefit from this research.
As a bioinformatics or biological data science researcher, my research focuses on mass spectrometry data, which involves comprehensive profiling of proteins, metabolites, and lipids in tumors or blood. This is a fairly specialized field, yet even here, there’s the Cardinal R package tailored for spatial analyses. This progress is exciting and indicative of a significant trend in our field. This trajectory is not just a fleeting moment but a substantial shift that will persist and evolve, shaping the future of bioinformatics.
Please share any additional details you would like included in the blog.
If you have a neat package or tool you would like to showcase, and please feel free to reach out at paul.stewart@moffitt.org. This is a great way for trainees or junior data scientists to get a presentation on their CV.
Moffitt is consistently looking for talent on the academic research side and the operational side. For anyone who is interested, I’d recommend visiting the Moffitt website.
Our annual hackathon is set for December 12th and 13th, 2024. Details about the hackathon are forthcoming, but for those eager to stay informed, the best approach is to join our Bio-Data Club Meetup. We consistently post all the relevant updates there, ensuring you’re well-informed and prepared for the event. Mark your calendars for December 12th and 13th – it’s shaping to be an enriching and exciting experience!
How do I Join?
R Consortium’s R User Group and Small Conference Support Program (RUGS) provides grants to help R groups organize, share information, and support each other worldwide. We have given grants over the past four years, encompassing over 68,000 members in 33 countries. We would like to include you! Cash grants and meetup.com accounts are awarded based on the intended use of the funds and the amount of money available to distribute.
The recent R Validation Hub Community meeting brought together around 50 participants to explore the concept of “validation” within the R programming ecosystem. This session highlighted the diversity of validation perspectives, emphasizing the importance of tailored definitions across different roles, such as users, administrators, package developers, and regulatory agencies. Here are the key takeaways:
Key Insights:
Validation Perspectives: The meeting underscored the need for each organization to define “validation” in a way that suits its context, while the R Validation Hub offers a baseline for common understanding.
Statistical Methodology Challenges: Discussions acknowledged the challenges in achieving exact results across different programming languages due to inherent differences in statistical methodologies.
Open Source Contributions: The importance of returning testing code to package developers was highlighted, reinforcing the open-source ethos of collaboration and quality enhancement.
Resource Availability: The slides from the meeting are accessible on GitHub here. Although the meeting wasn’t recorded, the community is encouraged to join the R Validation Hub mailing list for future updates and meeting invites here.
Looking Forward:
The meeting reiterated the significance of the R Validation Hub as a central point for validation discussions and resources. Future community meetings are tentatively scheduled for May 21, August 20, and November 19, offering opportunities for further engagement and contribution to the evolving conversation around R validation.
Join the R Consortium for an enlightening webinar on March 20th, 2024, at 4:00 PM ET, featuring Mine Cetinkaya-Rundel, Professor of the Practice of Statistical Science at Duke University. Discover the innovative Quarto tool to streamline the creation of reproducible, publication-ready manuscripts.
Quarto Manuscripts Introduction: Learn how to easily integrate reproducibility into your research with Quarto’s user-friendly features, creating comprehensive bundled outputs ready for journal submission.
Interactive Demo: Witness a live demonstration of Quarto in action, showcasing how to enhance your current manuscript preparation process and address common challenges.
Expert Guidance: Gain insights from Mine Cetinkaya-Rundel’s extensive experience in statistical science and reproducible research, offering valuable tips for improving your workflow.
Event Details:
When: March 20th, 2024, at 4:00 PM ET
Don’t miss this opportunity to refine your manuscript preparation process with the latest advancements in reproducibility technology.
Nadejda Sero, the founder of the R Ladies Cotonou chapter, shared with the R Consortium her experiences learning R, the challenges of running an R community in a developing country, and her plans for 2024. She also emphasized the importance of considering the realities of the local R community when organizing an R User Group (RUG).
Please share about your background and involvement with the RUGS group.
My name is Nadejda Sero, and I am a plant population and theoretical ecologist. I have a Bachelor of Science in Forestry and Natural Resources Management and a Master of Science in Biostatistics from the University of Abomey-Calavi (Benin, West Africa). I discovered R during my Master’s studies in 2015. From the first coding class, I found R exciting and fun. However, as assignments became more challenging, I grew somewhat frustrated due to my lack of prior experience with a programming language.
So, I jumped on Twitter (current X). I tweeted, “The most exciting thing I ever did is learning how to code in R!” The tweet caught the attention of members of the R Ladies global team. They asked if I was interested in spreading #rstats love with the women’s community in Benin. I was thrilled by the opportunity and thus began my journey with R-Ladies Global.
The early days were challenging due to the novelty of the experience. I did not know much about community building and social events organization. I started learning about the R-Ladies community and available resources. The most significant work was adjusting the resources/tools used by other chapters to fit my realities in Benin. My country, a small French-speaking developing African country, had poor internet access and few organizations focused on gender minorities. (We are doing slightly better now.) On top of that, I often needed to translate some materials into French for the chapter.
As I struggled to make headway, the R-Ladies team launched a mentoring program for organizers. I was fortunate enough to participate in the pilot mentorship. The program helped me understand how to identify, adjust, and use the most effective tools for R-Ladies Cotonou. I also gained confidence as an organizer and with community work. With my fantastic mentor’s help, I revived the local chapter of R-Ladies in Cotonou, Benin. I later joined her in the R-Ladies Global team to manage the mentoring program. You can read more about my mentoring experience on the R-Ladies Global blog.
Happy members of R-Ladies Cotonou sharing some pastries after the presentation. At our first official meetup, the attendees discovered and learned everything about R-Ladies Global and R-Ladies Cotonou.
I am grateful for the opportunity to have been a part of the R-Ladies community these last six years. I also discovered other fantastic groups like AfricaR. I am particularly proud of the journey with R-Ladies Cotonou. I am also thankful to the people who support us and contribute to keeping R-Ladies Cotonou alive.
Can you share what the R community is like in Benin?
R has been commonly used in academia and more moderately in the professional world over the past 2-3 years. For example, I worked with people from different areas of science. I worked in a laboratory where people came to us needing data analysts or biostatisticians. We always used R for such tasks, and many registered in R training sessions. The participants of these sessions also came from the professional world and public health. I have been out of the country for a while now, but the R community is booming. More people are interested in learning and using R in different settings and fields. I recently heard that people are fascinated with R for machine learning and artificial intelligence. It is exciting to see that people are integrating R into various fields. There are also a few more training opportunities for R enthusiasts.
Can you tell us about your plans for the R Ladies Cotonou for the new year?
More meetups from our Beninese community, other R-Ladies chapters, and allies.
We are planning a series of meetups that feature students from the training “Science des Données au Féminin en Afrique,” a data science with R program for francophone women organized by the Benin chapter of OWSD (Organization for Women in Science for the Developing World). We have three initial speakers for the series: the student who won the excellence prize and the two grantees from R-Ladies Cotonou. The program is an online training requiring good internet, which is unfortunately expensive and unreliable. If you want good internet, you must pay the price.
R-Ladies Cotonou supported two students (from Benin and Burkina Faso) by creating a small “internet access” grant using the R Consortium grant received in 2020.
The meetup speaker is taking us through a review of the most practical methods of importing and exporting datasets in R. The attendees are listening and taking notes.
This next series of meetups will focus on R tutorials with a bonus. The speakers will additionally share their stories embracing R through the training. The first speaker, Jospine Doris Abadassi, will discuss dashboard creation with Shiny and its potential applications to public health. I hope more folks from the training join the series to share their favorite R tools.
I believe these meetups will assist in expanding not only the R-Ladies but the entire R community. I particularly enjoy it when local people share what they have learned. It further motivates the participants to be bold with R.
About “Science des Données au Féminin en Afrique“, it is the first time I know that a data science training is free for specifically African women from French-speaking areas. Initiated by Dr. Bernice Bancole and Prof. Thierry Warin, the program trains 100 African francophone women in data science using R, emphasizing projects focused on societal problem resolution. The training concluded its first batch and is now recruiting for the second round. So, the community has expanded, and a few more people are using R. I appreciate that the training focuses on helping people develop projects that address societal issues. I believe that it enriches the community.
As I said in my last interview with the R consortium, “In some parts of the world, before expecting to find R users or a vivid R community, you first need to create favorable conditions for their birth – teach people what R is and its usefulness in professional, academic, and even artistic life.” It is especially true in Benin, whose official language is French. English is at least a third language for the average multilingual Beninese. Many people are uncomfortable or restrained in using R since most R materials are in English. I hope this OWSD Benin training receives all the contributions to keep running long-term. You can reach the leading team at owsd.benin@gmail.com.
Our other plan is to collaborate with other R-Ladies chapters and RUGS who speak French. If you speak French and want to teach us something, please email cotonou@rladies.org.
Otherwise, I will be working on welcoming and assisting new organizers for our chapter. So, for anyone interested, please email cotonou@rladies.org.
Are you guys currently hosting your events online or in-person? And what are your plans for hosting events in 2024?
We used to hold in-person events when we started. Then, the COVID-19 pandemic hit, and we had to decide whether to hold events online. Organizing online events became challenging due to Cotonou’s lack of reliable internet access or expensive packages. As a result, we only held one online event with poor attendance. We took a long break from our activities.
Going forward, our events will be hybrid, a mix of in-person and online events. In-person events will allow attendees to use the existing infrastructure of computers and internet access of our allies. It also offers an opportunity to interact with participants. Therefore, I am working with people in Cotonou to identify locations with consistent internet access where attendees can go to attend the meetups. Online events will be necessary to accommodate speakers from outside of the country. It will be open to attendees unable to make it in person.
Any techniques you recommend using for planning for or during the event? (Github, zoom, other) Can these techniques be used to make your group more inclusive to people that are unable to attend physical events in the future?
The techniques and tools should depend on the realities of the community. What language is comfortable for attendees? What meeting modality, online or in person, works best for participants?
As mentioned earlier, I was inexperienced, and organizing a chapter was daunting. My mentoring experience shifted my perspective. I realized that I needed to adjust many available resources/tools. Organizing meetups became easier as I integrated all these factors.
For example, our chapter prioritizes other communication and advertisement tools like regular emails and WhatsApp. The group is mildly active on social media, where the R community is alive (X/Twitter, Mastodon). It is easier to have a WhatsApp group to share information due to its popularity within our community. We recently created an Instagram account and will get LinkedIn and Facebook pages (with more co-organizers). I would love a website to centralize everything related to R-Ladies Cotonou. Using emails is an adjustment to Meetup, which is unpopular in Benin. Getting sponsors or partners and providing a few small grants for good internet would help tremendously our future online events.
Adjusting helps us to reach people where they are. It is imperative to consider the community, its realities, and its needs. I often asked our meetup participants their expectations, “What do you anticipate from us?” “What would you like to see in the future?” Then, I take notes. Also, we have Google Forms to collect comments, suggestions, potential speakers, contributors, and preferred meeting times. It is crucial to encourage people to participate, especially gender minorities less accustomed to such gatherings.
I have also attempted to make the meetups more welcoming and friendly in recent years. I always had some food/snacks and drinks available (thanks to friends and allies). It helps make people feel at ease and focus better. I hope the tradition continues for in-person meetups. It is valuable to make the meetups welcoming and friendly. How people feel is essential. If they come and feel like it is a regular lecture or course, they may decide to skip it. But, if they come to the meetup and learn while having fun, or at the very least, enjoy it a little, it benefits everyone.
These are some of the key aspects to consider when organizing a meetup. It is critical to consider the people since you are doing it for them. Also, make sure you have support and many co-organizers if possible.
All materials live on our GitHub page for people who can’t attend physical events. Another solution would be recording and uploading the session on the R-Ladies Global YouTube or our channel.
What industry are you currently in? How do you use R in your work?
I am now a Ph.D. student in Ecology and Evolutionary Biology at the University of Tennessee in Knoxville.
R has no longer been my first programming language since I started graduate school. I still use R for data tidying data analysis but less extensively. I worked a lot with R as a master’s student and Biostatistician. It was constant learning and growth as a programmer. I had a lot of fun writing my first local package. However, I now work more with mathematical software like Maple and Mathematica. I wish R were as smooth and intuitive as this software for mathematical modeling. I like translating Maple code to R code, especially when I need to make visualizations.
I am addicted to ggplot2 for graphs. I love learning new programming languages but am really attached to R (it’s a 9-year-old relationship now). I developed many skills while programming in R. R helped me become intuitive, a fast learner, and sharp with other programming languages.
My most recent project that utilized R, from beginning to end, was a project in my current lab on the evolutionary strategies of plants in stochastic environments. We used R for demographic data tidying and wrangling. Data analysis was a mix of statistical and mathematical models. It was a good occasion to practice writing functions and use new packages. I enjoy writing functions for any task to automate repetitive tasks, which reduces the need for copying and pasting code. I also learned more subtleties in analyzing demographic data from my advisor and colleagues who have used R longer.
How do I Join?
R Consortium’s R User Group and Small Conference Support Program (RUGS) provides grants to help R groups organize, share information, and support each other worldwide. We have given grants over the past four years, encompassing over 68,000 members in 33 countries. We would like to include you! Cash grants and meetup.com accounts are awarded based on the intended use of the funds and the amount of money available to distribute.