Citizen science is a critical engine for creating professional tools that become new standards in epidemic outbreak response. The problem is connecting people on the front lines – “COVID-19 response agents” – and people with R language skills.
The R Consortium awarded RECON a grant for $23,300 in the summer of 2019 to develop the RECON COVID-19 challenge, a project aiming to centralise, organise and manage needs for analytics resources in R to support the response to COVID-19 worldwide.
The COVID-19 challenge is an online platform whose goal is to connect members of the R community, R package developers and field agents working on the response to COVID-19 who use R to help them fill-in their R related needs.
Field agents include epidemiologists, statisticians, mathematical modellers and more.
The platform provides a single place for field agents to give feedback in real time on their analytical needs such as requesting specific analysis templates, new functions, new method implementation, etc. These requests are then compiled and organized by order of priority for package developers and members of the R community to browse and help contribute to.
One example is scoringutils. The scoringutils package is currently used by research teams in the UK and US. It is also set to be deployed on a larger scale as part of the evaluation for the US Forecast Hub which is the data source for the official CDC COVID-19 Forecasting page.
As COVID-19 continues to impact people’s lives, we are interested in predicting case trends of the near future. Trying to predict an epidemic is certainly no easy task. While challenging, we explore a variety of modeling approaches and compare their relative performance in predicting case trends. In our methodology, we focus on using data of the past few weeks to predict the data of next week. In this blog, we first talk about the data, how it is formatted and managed, and then describe the various models that we investigated.
Data
The data we use records the number of new cases reported in each county of the U.S everyday. Even though the dataset that we use has much more information, like the number of recovered deaths, etc, the columns that we focus on are “Cases”, “Date”, “State”, and “County”. We combine the “State” and “County” columns together into a single column named “geo.” After that, we decided to use the 2 weeks from 05/21/2020 to 06/03/2020 as training data, to try to predict the median number of cases from 06/04/2020 to 06/10/2020.
We obtain the following table for training set:
To trim down the data, we remove all counties that have less than 10 cases in the 2 training weeks. The final dataset has 1521 counties in total, which is around half of 3,141 total counties in the US.
Projection Method
The first method that we look into is the Friedman’s Supersmoother method. This is a nonparametric estimator based on local linear regression. Using a series of these regressions, the Projection method is able to generate a smoothed line for our time series data. Below is an example of the smoother on COVID case data from King county in Washington State:
As part of our methods for prediction, we use the last 2 points fitted by the smoother to compute a slope, and then use this slope to predict the number of cases for next week. We find that Friedman’s Supersmoother method is consistent and easy to use because it does not require any parameters. However, we have found that outliers can cause the method to sometimes have erratic behavior.
Generalized Linear Model
In this approach, we will use R’s built-in generalized linear model function, glm. GLMs generalize the linear model paradigm by introducing a link function to accommodate data which cannot be fit with a normal distribution. The link function transforms a linear predictor to enable the fit. The type of link function used is specified by the “family” parameter in R’s GLM function. As is usual with count data, we use family=”poisson”. A good introduction can be found at The General Linear Model (GLM): A gentle introduction. One drawback of this approach is that our model could be too sensitive to outliers. To combat against this, we experiment two approaches: Cook’s Distance and Forward Search.
Cook’s Distance:
This method is quite straightforward and can be summarized in 3 steps:
Fit a GLM model.
Calculate Cook’s distance, which measures the influence of each data point, for all 14 points. Remove high influence points where data is far away from the fitted line.
Fit a GLM model again based on the remaining data.
One caveat of this method is that the model might not converge in the first step. Though, such cases are rare if we only use 2 weeks of training data. A longer training period may cause the linear predictor structure to prove too limited and require other methods.
Forward Search:
The Forward Search method is adapted from the second chapter of the text “Robust Diagnostic Regression Analysis,” written by Anthony Atkinson and Marco Riani. In Forward Search, we start with a model fit to a subset of the data. The goal is to start with a model that is very unlikely to be built on data that includes outliers. In our case, there are few enough points that we can build a set of models based on every pair of points; or select a random sample to speed up the process. Out of these, we choose the model that best fits the data. Then, the method will iteratively and greedily select data points to add into the model. In each step, the deviance of the data points from the fitted line is recorded. A steep jump in deviance implies that the newly added data is an outlier. Let’s look at this method in further detail:
1. Find initial model using the following steps:
a. Build models on any combination of 2 data points. Since we have 14 data points in total, we will have (14 choose 2) = 91 candidate models.
b. Compute the trimmed sum squared error of the 14 data points based on each fitted model. (Trimmed here means that we only use the 11 data points with least squared error. The intention is to ignore outliers when fitting)
c. The model with least trimmed squared error is selected as the initial model.
For explanation, let’s assume that this red line below was chosen as the initial model. This means that out of all the pairings of two points, this model, more or less, fit the data the best.
2. Next, we walk through and add the data points to our initial model. The process is as follows:
a. Record the deviance of all 14 data points to the existing model
b. Using the points with the lowest deviations from the current model, select the subset with one additional point for fitting the next model in the sequence
c. Using the newly fit model, repeat this process iteratively on the rest of the data
3. We want to evaluate the results of step 2 by looking at the recorded deviance from each substep. Once there seems to be a steep jump in the recorded deviance (above 1.5 SDs), this indicates that we’ve reached an outlier. The steep jump indicates this because, compared to the model before that does not include the outlier, the newly created model with the outlier shifted the model & the recorded deviance significantly—suggesting that this data point is unlike the rest of the data. Additionally, we can presume that the remaining points after the steep jump are more aligned to the skewed data and could also be treated as outliers.
4. Ignoring the outliers identified in step 3, use the remaining data set as training data for the GLM and fit the final model.
Using this method, we will always be able to get a converged model. However, the first step of selecting the best initial model can be very time consuming and the time complexity is O(N^2), where N is the number of data points in the training set. One way to reduce the runtime is to use a sample of possible combinations. In our example, we may try 10 combinations out of the potential 91 combinations.
Moving Average
Our next approach is a simplified version of Moving Average. For this, we first compute the average of the first training week, and then compute the average of the second training week. Here, we assume that the change in number of cases reported each day has a linear relationship. While simple, using a moving average can obtain decent results with strong performance. Below is a visual representation of this method. The first red point represents the average of the first week and the second represents the average of the second week. The slope of the two points is then used to project the following week.
Results
To evaluate these approaches, we used each method to project the median number of cases for the next week based on the case data from the previous two weeks. In addition, we also analyzed the model in terms of a classification problem—taking a look at whether each model was able to correctly identify whether the case trend was increasing or decreasing. Doing this over all of the counties in our dataset, each method now has a list of 1521 projected medians. Comparing the projections to actual data, we can calculate the observed median error for each county across the methods. The table below displays the percentiles of each method’s list of errors.
Note that it is quite common for the Moving Average and Projection methods to predict a negative number of cases. In those situations, we will force them to predict 0. It is common for both GLM models to produce an extremely large number of cases.
Overall, the GLM model, utilizing Cook’s Distance to find outliers, seems to perform best. This method rarely makes negative predictions and predicts reasonably in most cases. The Moving Average method produced the lowest 100th Percentile, or in other terms, achieved the lowest maximum error. The traditional model-based Cooks Distance method improves on the simple Moving Average approach in most cases. All methods, however, suffer from a number of very unrealistic estimates in some cases. Although the Forward Search method is interesting for its innovative approach, in practice it underperforms and is more costly in terms of compute time.
Now, let’s take a look at the results of our classification problem:
Interestingly, the GLM models seemed to not perform as well when looking at the problem in terms of correctly classifying increasing or decreasing trends universally across the counties. There are two metrics in the table above. The “ROC AUC (>5)” calculates the metric when applied to counties with their previous week’s median case count above 5, whereas the “ROC AUC (>25)” refers to above 25 cases (ROC AUC, which you can read more about here, is a metric for measuring the success of a binary classification model; values closer to 1 indicate better performance). What you can infer from this is that the more simple Moving Average and Projection methods can do better than the GLMs as a blanket approach. However, when looking at counties with more cases, and likely more significant trends, the GLMs prove better. This supports the finding that GLMs can often have erroneous results on insufficient datasets, but good results on datasets with enough quality data. Additionally, we can say that this is a good example to demonstrate that one-size does not fit all when it comes to modelling. Each method has its benefits and it is important to explore those pros and cons when making a decision on what model to use, and when to use it.
Visual Analysis
For a more visual look at the results, we can examine some specific cases. Here, we plot results of the methods on three different scenarios: where the number of cases is less than 50, between 50 and 150, and greater than 150.
In general, it can be seen that the more cases there are in the training set, the more accurate and reasonable are the GLM methods. These perform particularly well when there is a clear trend of increasing or decreasing data. However, the GLM does a poor job when the cases are reported on an inconsistent basis (data on some days, but 0’s on others). In such cases, the fitted curve is “dragged” by the few days of reported data. An example of this is illustrated by the Texas Pecos data in the second figure above.
The Projection method seems to be too subjective to the case counts on the last few days. When there is a sharp decrease on those days, the supersmoother may make negative predictions.
The Moving Average method can be interpreted as a simplified version of the supersmoother. The main difference is that it weights the data of the first and second week equally when making predictions. Therefore, it actually does a slightly better job than the supersmoother.
Effect of Training Period:
To further evaluate these approaches, we can extend the length of the training weeks to see how that might affect the performance of each model. The metric used here is similar to the table from the “Results” section: the median error of the model prediction from the observed data. The results across different training lengths are below:
It is interesting to see that the performance of the GLM-CD model first increases as the length of training data increases (deviances decrease), but later the performance deteriorates once the length of training data is too large.
The following examples illustrate why the performance may deteriorate when the length of training data is too long:
We can see that the GLM model assumes that the trend must be monotone. Once it assumes that the number of cases are increasing, it fails to detect the decreasing number of cases after the outbreak. Therefore, the GLM model is particularly useful when making predictions based solely on the most recent trend. On the contrary, the Projection method is much better at automatically emphasizing the most recent trend, without having to worry about whether the data is monotonic or not, and increasing the length of training data increases its performance in general.
The GLM approach could also be improved by taking into account the presence of a maximum and only using the monotonic portion of the data. For example, the gamlss package and function have a feature that can detect a changepoint and fit a piecewise linear function appropriately. (See Flexible Regression and Smoothing using GAMLSS in R pp 250-253). This would enable us to use a longer time frame when possible in an automated way.
Overall, if we want to use the most recent data for nearcasting based on a GLM model, a 6 week training set seems to be the optimal length. If we were to use a longer period of training data, we might prefer using the Projection method.
Conclusion:
While each model has its advantages and disadvantages, using these approaches can help establish reasonable predictions about future trends in COVID data. Not only can these methods be applied in this specific case, but they can also be used for a number of different use cases involving time series data.
The methodologies used in this analysis were created in R and Spotfire. To run these yourself, simply utilize Spotfire’s data function, which allows you to run R (or python) scripts within the application. For more information on data functions, check out our community, and if you are interested in learning more about our COVID work and what happens under the hood in Spotfire, read here.
Acknowledgments:
A special thanks to Zongyuan Chen, David Katz, and the rest of the team for their contributions.
R0, the basic reproduction number, and Rt, the time-varying reproduction number, are quantities used when trying to understand the reproduction rate of the virus. However, both of them are quite difficult to estimate. One glaring issue is the largely unknown prevalence of asymptomatic and presymptomatic cases, which directly impacts our estimates. Another issue is the extent of local versus imported cases (read here for more information on R0/Rt).
A complementary approach to estimating R0 is to consider the reported cases as a random variable, and seek to characterize it directly. This is often done with some form of moving average. Moving average has its advantages—it is familiar and easy to understand. However, it has several disadvantages:
We must choose a bandwidth – the number of days to include in the average. How should we do this?
We do not get an estimate of the stability of the predictions we obtain.
Averages are quite sensitive to outliers, resulting in swings that are difficult to interpret.
At TIBCO, we have been using Friedman’s SuperSmoother (as implemented in R as supsmu) to estimate the epidemic curve of counties, states/provinces, and countries across the world. This has the default option to choose the bandwidth automatically. In most cases, this method appears to match or outperform the moving average method.
One important output that we’d like to get from this exercise is an estimate of the current trend, but this proves challenging for many methods. We have performed a number of experiments to compare various bandwidths and methods for extrapolating into the near future, including the SuperSmoother and GAM/Poisson models (we delve into those results in a separate study). Today, we focus on what we have found to be the most effective method for estimating the current trend: GAMLSS.
GAMLSS
In this blog, we describe our experience with a method called GAMLSS, Generalized Additive Models for Location, Scale and Shape, available in R as package gamlss. Our intention is to provide insight into the overall history, variation, and current trend in COVID data; prediction is not necessarily our focus. This method is described by Stasinopoulos et. al. as a distributional approach—that is, we make an informed guess as to the appropriate distribution to use, and then fit a linear or smooth model via a link function to the data. We use penalized b-splines to fit the time series of new cases with a smooth curve (this method creates a smooth curve adapted to the data). The gamlss package additionally provides easy to use diagnostics to help validate our hypothesis and the fit.
To begin, we apply this method to the daily counts of New Cases from Johns Hopkins as well as the websites of various countries. Initially we use the data by State and Province from around the world. For each geography, defined as ‘country’+’State/Province’, we use the gamlss::fitDist function to find the distribution that best fits the data. We found that “SHAHSo” was a promising choice–“sinh-arcsinh original”. This is a flexible distribution with 4 parameters that control its location, scale and shape.
We fit the data as follows:
Model <- gamlss(New.Cases ~ pb(as.numeric(Date)),
sigma.formula= ~ pb(as.numeric(Date)),
data = train.data,
family=SHASHo())
GAMLSS allows a separate model formula for each of its parameters. On line 1, we model the mu parameter as a smooth curve pb(), which uses a penalized b-spline, with the degree of smoothing selected by cross-validation. The sigma parameter on line 2 is modelled with the same formula. This is a particular advantage of this method, since we do not have to assume constant values for the parameters. Here we have specified a model of the variance changing over time. We see this clearly in the plots below.
Two more parameters, nu and tau, are omitted from this specification, which results in the default, a constant for each of these.
We check the fit by inspecting plot(Model):
These plots show the quantile residuals in various ways. Normalized quantile residuals are transformations of the observed residuals that use the quantiles for the chosen distribution. The effect is that the transformed residuals are normally distributed if the model is correct. You see that this is true when looking at the normal-shaped bell curve in the Density Estimate above, and in the Normal Q-Q plot, where a roughly straight line indicates that the residuals are normally distributed. We find that in many cases, we are able to create adequate models with healthy diagnostics. These models are then used to predict the distribution of values we can expect to see on each date.
Because we have such a model, we use the centiles of the distribution to plot contour lines for any centile. This gives us not only the center of the distribution, but also graphically shows the distribution of confidence intervals. Here is one example:
In this plot, the dots represent the observed values of new cases across the state of Virginia. The output of the GAMLSS model provides a range of outcomes at a certain point in time. Each line in the visualization represents the plot of the nth percentile and the value here is that these can be used to create confidence intervals about the actual trend of the data.
We see an interesting increase in the modelled variance, followed by a relative decrease. We speculate that these high daily counts may indicate highly localized outbreaks in an area, building or event, or timing issues caused by new sets of tests being administered. With sufficient data, the model captures these events as part of its error distribution.
As a means of validating our approach, we use 153 geographic areas for which we developed adequate models. We use 7 days of available data as a hold-out sample, and project our results forward for comparison with the percentiles we predicted. We tag each new observation into the band that it falls into and compare the percentiles of this test data set with the expected percentiles:
Each point (dot) represents a group of observations whose predictions fall into a range of counts. The y-axis is the actual result expressed as a percentile. The line is y=x, perfect agreement between expected and actual.
The observed percentiles agree well with a random set of draws from the predicted distribution. For example, 44% of the actual counts fall below the median predicted for its day and geo. We conclude that extrapolating from such models gives a reasonable expectation of the range of results we are likely to see in the coming week.
We decide to use these percentile plots in TIBCO’s COVID Live Report whenever we are able to fit a good model. In most cases, failures are due to insufficient data, which could be seen as a drawback for the approach. We recognize that the GAMLSS, despite its clear advantages, is not adept at dealing with all types of data. Like any method, it is important to understand its advantages and disadvantages, and when to know how to utilize it.
GAMLSS in TIBCO’s COVID-19 Live Report
Using GAMLSS to fit epidemic curves and predict future cases/deaths over the next week is a new feature in TIBCO’s COVID-19 Live Report. Because GAMLSS does really well at capturing the current trend, a side effect is that the method is able to produce promising estimates about future data. By clicking the “View Forecasts” button on the Live Report’s home page, you are directed to a tab where you can explore the results of our GAMLSS method. On this page, you can choose one or more states/provinces, counties, or countries, and a GAMLSS model will fit to the selected data and provide predictions for the next 7 days. The following is the GAMLSS plot on California’s case counts:
The GAMLSS plot has three lines, one for the 10th, 50th, and 90th centiles. This is a benefit of the GAMLSS method as you are not only able to view the center of distribution, represented by the solid line, but you can also see the distribution of confidence values with the 10th and 90th centiles, represented by the dotted lines. Instead of being limited to just one prediction forecast, the GAMLSS model gives you a range of possibilities of what might happen over the next 7 days, as seen in red.
Conclusion
After some experimentation, we found that the GAMLSS method is an effective approach for understanding trends in COVID data. Due to the method’s unique distributional approach and solid statistical foundations, the GAMLSS improves on other more popular methods like Moving Average for fitting epidemic curves and making predictions. GAMLSS provides a credible estimate of the variance at each point in time and the distribution of expected values in the near future, something lacking in other methods. For more information on GAMLSS, be sure to check out the references below and explore the method on TIBCO’s dashboard.
TIBCO Spotfire is a unique platform that combines advanced visualization and data science techniques. The culmination of its capabilities can be demonstrated in TIBCO’s COVID-19 Visual Analysis Hub. Allowing complex algorithms to run in the background, the application boasts a simple, interactive interface that lets any type of user learn more about the current state of the pandemic. In this blog, we will take a deeper look at the inner workings of the dashboard and explore some of Spotfire’s special functionality, as well as some technical and statistical innovations.
This high-level blog is split into three sections: Data Science Functions, Data Visualization Methods, and Data Engineering(coming soon). Within each section, there will be subsections where you can learn more about specific tools & methods that we used. In addition, some of these subsections will contain links to more detailed blogs—allowing you to read content tailored to your interests.
Feel free to have a look at our Visual Analysis Hub to get a better idea of the work that went behind building it.
Details on Hub’s Data Science Functions
There is much uncertainty about the current state of the pandemic. Recent outbreaks across the world prove that it is hard to pinpoint and contain the coronavirus. Here at TIBCO, our recent work has been focused on trying to make tangible estimates about the actual trends in the data, while also facing the reality that there is only so much that we can be certain about.
One road towards understanding the coronavirus is trying to fit the epidemic curve of the data.
Due to its nature, the case and death data that we observe can be sporadic, confusing, and can take on many different shapes. For creating fit lines, we have adopted two different methodologies: Friedman’s Supersmoother and GAMLSS, a modified version of generalized linear models. This work is done to create the lines seen above, which you can interpret as a summarization of how the data has evolved over time.
Friedman’s Supersmoother:
A large, persistent issue that we continue to face with case growth analysis is the flood of bad/missing data as well as misreported or non-reported data. Some regions have had weird spikes, some have had thousands of cases reported the day after 0 cases were reported (misreporting), etc. In order to overcome these mishaps, we need to use methods that focus on the overall trend of the data and do their best to ignore the noise. As such, we have experimented with different smoothing methods including moving averages and LOESS, but eventually settled on Friedman’s Supersmoother due to its ability to overcome outliers and its lack of hyperparameter tuning. Our implementation of the method used the ‘supsmu’ function found in R’s stats package. Below is a snippet of our code:
Snippet of R Code for Supersmoothing in the COVID-19 Application
In more technical detail, the Supsmu function is a running line smoother that chooses a variable k such that there are k/2 data points on each side of the predicted point. k can be any number between (0.01)*n and n, where n is the number of total data points. If the span itself is specified, the function implements a single smoother with (inputted span)*n used as the span (Friedman, 1984). We run this method for each set of dates in each region using data.table in R and then append the results back into the original data with each region’s corresponding smooth values.
Friedman’s Supersmoother helps to give a relatively noise-free smooth curve that can model the case growth well across regions and differently shaped data. Additionally, we have noticed that the method has adapted well over time. Since surpassing ~six months of data, the input size that is fed into the supersmoother has become quite sufficient and therefore has created increasingly accurate fit curves.
GAMLSS/Nearcasting:
The other method we have explored is GAMLSS, Generalized Additive Models for Location Scale and Shape. This method is valuable and has become one of our favorites because it includes a notion of uncertainty when fitting models on data. Rather than making concrete estimates/predictions about the data, the GAMLSS method provides a range of possible outcomes at any given point in time. You are not just looking at one line that assumes the true shape of the data, but instead you can look and explore multiple estimates of what the trends might look like. For more detailed information about GAMLSS and our processes, we have written a whole blog on the subject, so please check it out!
Another important question that many people want to understand is how COVID-19 trends are going to look like in the near future. To try and answer that question, we experimented with some common and uncommon methods for predicting the amount of coronavirus cases in the next week. An interesting challenge that emerged was the process of choosing an approach for dealing with inconsistent reporting and outliers when modeling. We discovered that some lesser known modeling techniques can prove to be advantageous under certain conditions. You can read the results of our analysis here.
GAMLSS Model Evaluated on California (10/28)
In our Live Report, we use GAMLSS through data functions in Spotfire as a way to fit epidemic curves and make predictions over the next week based on the current trends. Above is an example of running GAMLSS on parts of the San Francisco Bay Area. By choosing counties in the left panel, the coronavirus case data associated with these regions is sent as an input into a data function that creates and runs the models. Inside that data function, we are simply running code written in R that will output three epidemic curves fit to the input data (one for the 10th, 50th, and 90th percentile of the GAMLSS model–the ‘range’ of outcomes). These output lines are then overlaid with the case data on the bottom right panel of our page. Easily configured with visualizations, the data function is capable of running its complex scripts over an interactive user interface. This page can be accessed from the home page by clicking on the “View Forecasts” button. To learn more about how you can integrate R and Python functions with Spotfire, check out our community.
The integration of data science functions in TIBCO’s COVID application demonstrates Spotfire’s ability to coincide statistical analysis with a visual framework. Next, we will take a look at the data visualization techniques used in our dashboard.
Details on Hub’s Visual Functions
Business Reopenings:
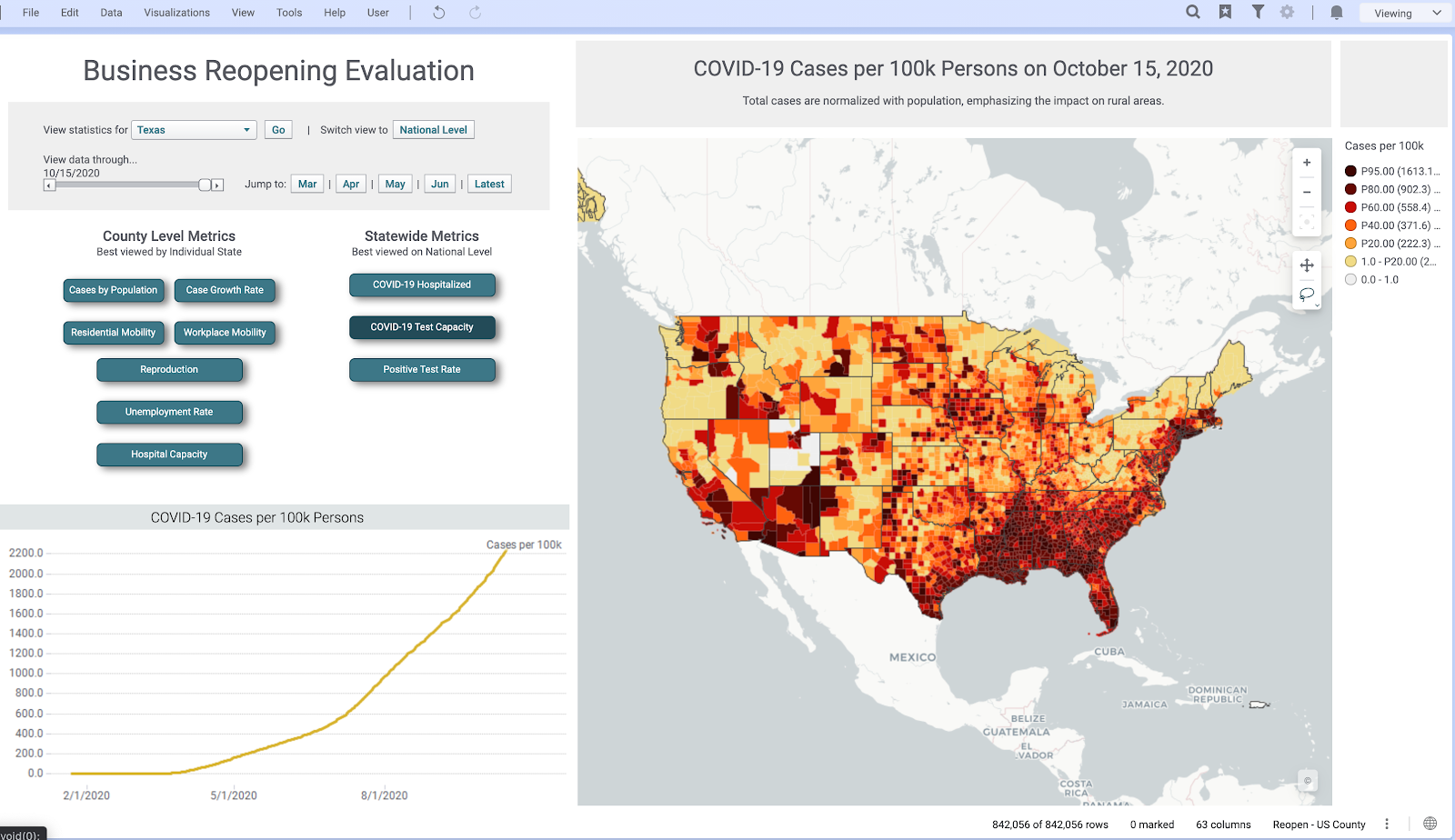
Keeping in mind that each country, and each province within each country, might have different rules and regulations regarding reopening, businesses need a view of all essential metrics that can help them understand the current situation in their region—subsequently assisting them to plan a reopening according to local rules and regulations. To help supplement this decision-making, we created a ‘Business Reopening’ page on our application that provides a one-stop look at all the essential metrics. Through interactive buttons, sliders, and maps, users can evaluate how the pandemic is progressing in their region.
Above is a look at our ‘Business Reopening’ page. This page includes deep drills into unemployment rates, case growth, and mobility—all from different verified sources. In its many interactive features, there is the capability to switch abstraction levels from a geographical perspective, filter results by circling areas on the map, and adjust a slider to look at the analysis at different points in time. Under the hood, when these interactive elements are invoked, the command is sent to a Spotfire data function, which recomputes the analysis and sends the results back to the now updated visualizations.
Here are some examples of different county level metrics we have in the page. All of these can be drilled down into a specific state or at the national level and have detailed views for both:
Reproduction estimates at the County Level
Workplace Mobility in different counties in the State of Virginia
Natural-Language Generation (NLG):
To make the COVID-19 Hub more accessible and understandable for any type of user, we utilize Arria’s NLG (natural-language generation) tools across our application. NLG augments the analysis by building a narrative that is not just charts and graphs, but instead generates detailed insight into what is happening through language.
By gathering information from the data, the NLG tool is able to produce sentences that summarize the data, and do so without making the text sound like it came from a robot. In an excerpt from TIBCO’s website, Arria NLG is described, “Through algorithms and modeling, Arria software replicates the human process of expertly analyzing and communicating data insights—dynamically turning data into written or spoken narrative—at machine speed and massive scale.” The NLG tool is available as a visualization type within Spotfire.
Newspaper style:
The COVID-19 Application uses what is called a Newspaper style layout for visualization within Spotfire. This layout helps in overcoming limitations that can come from a fixed length layout. For example, if a page of an application is non-scrollable, it doesn’t allow you to add as many charts and visualizations as you might want. Instead, you are limited to charts that would be visible to the naked eye and that could fit into the size of a page. The Newspaper style format in Spotfire benefits in making it possible to add as many visualizations as you want and present a logical flow of information that can enrich your insights.
You can easily configure Spotfire’s Page Layout options to extend the page length to make your dashboard newspaper style and take advantage of all the real estate that you can get. This is done by right-clicking on the page navigation bar and configuring the Page Layout to your desire (video tutorial). Here is a quick GIF of how we use newspaper style formats in the COVID-19 Application:
Summary and Future Work
There are many dimensions needed to understand an issue as complex as the coronavirus pandemic. From analyzing hospitalization data to visualizing epidemic curves, TIBCO’s Visual Analysis Hub converges data science, data visualization, and data engineering in one central application. Utilizing Spotfire, these disciplines are used in harmony to deliver insights about the state of the pandemic to just about any type of user. We hope that you were able to learn a bit more about the statistical and technical work that went into our Visual Analysis Hub.
This blog will serve as the central location for any more blogs/updates regarding the development of our COVID dashboard, so be sure to come back and read more about the work that we have done!
Here, again, are the links to the topic-focused blogs:
Thank you to everyone who has contributed to the COVID Visual Analytics Hub and, in particular, a shout out to David Katz, Prem Shah, Neil Kanungo, Zongyuan Chen, Michael O’Connell, and Steven Hillion for their contributions towards creating these blogs and analyses.
The R Consortium’s COVID-19 Working Group is providing a new home for the COVID-19 Data Hub Project. The goal of the COVID-19 Data Hub is to provide the worldwide research community with a unified dataset by collecting worldwide fine-grained case data, merged with external variables helpful for a better understanding of COVID-19.
An initial award of $5,000 will be used to pay storage and maintenance fees for the growing number of international COVID-19 case level data sets. Additionally, the R Consortium will be assuming responsibility for organizing R Community efforts to maintain and develop the site.
When asked about the importance of the project, R Consortium Director Joseph Rickert replied, “I am very pleased that the R Consortium is in a position to make a practical contribution to combating the pandemic. Although, we all hope that the new vaccines will bring the world to some semblance of normality next year, it is likely that the virus will be with us for some time and the need to collect and curate data will continue.”
Created last April by Emanuele Guidotti, doctoral assistant at the Institute for Financial Analysis at the University of Neuchatel, in collaboration with David Ardia, professor at HEC Montreal, the COVID-19 Data Hub Platform is a critical tool for accessing data related to the virus, and looks to establish cooperation and participation with the scientific community around the world. Professors Eric Suess and Ayona Chatterjee of the Department of Statistics and Biostatistics at the California State University East Bay will be joining this effort.
To date, the data has been downloaded 3 million times.
From the full article:
“Working for a research project on COVID-19, I realized the difficulty of accessing data related to the virus,” said Guidotti. The source is heterogeneous: depending on the country, information is disclosed in different languages and formats. To unify them, Guidotti developed the very first prototype of the COVID-19 Data Hub platform in the spring. “This work was originally part of a research paper that was subsequently published in Springer Natureand featured on the Joint Research Center website,” he said. Thanks to the collaboration of David Ardia, the platform received financial support from the Canadian Institute for the Valorization of Data IVADO and HEC Montréal.
Thurs, December 10th, 9am PDT/12pm EDT/18:00 CEST – Register now!
Hosted by the COVID-19 Data Forum/Stanford Data Science Initiative/R Consortium
Join the R Consortium and learn about mobility data in monitoring and forecasting COVID-19. COVID-19 is the first global pandemic to occur in the age of big data. All around the world, public health officials are testing and releasing data to the public, giving ample cases for scientists to analyze and forecast in real-time.
Despite having so much data available, the data itself has been limited by simplistic metrics rather than higher dimensional patient-level data. To understand how COVID-19 works within the body and is transmitted, scientists must understand why the virus causes harm to some more than others.
Sharing this type of data brings up patient confidentiality issues, making it difficult to get this type of vital data.
The COVID-19 Data Forum, a collaboration between Stanford University and the R Consortium, will discuss the ways in which people’s mobility data holds promises and challenges in combating the spread of SARS-CoV-2, as well as how the public has behaved in response to the pandemic. This data is vital in understanding the way individual’s patterns have shifted since the pandemic, helping us to better understand where people are going and when they are getting sick.
The event is free and open to the public.
Speakers include:
Chris Volinksky, PhD Associate vice-president, Big Data Research, ATT Labs.
Caroline Buckee Associate Professor of Epidemiology and Associate Director of the Center for Communicable Disease Dynamics at the Harvard T.H. Chan School of Public Health.
Christophe Fraser Professor of Pathogen Dynamics at University of Oxford and Senior Group Leader at Big Data Institute, Oxford University, UK.
Andrew Schoeder, PhD Vice-president Research & Analytics for Direct Relief.
This November 2nd-7th, 2020, the 5th edition of the Brazilian Conference on Data Journalism and Digital Methods (Coda.Br) will be taking place with 50 national and international guest speakers and 16 workshops. Coda.Br is the largest data journalism conference in Latin America and this year will be completely online.
Organized by Open Knowledge Brasil and Escola de Dados (School of Data Brazil), Coda.Br boasts the support of multiple large scale associations including the Brazilian Association of Investigative Journalism (Abraji), R Consortium, Hivos Institute, Embassy of the Netherlands and the United States Consulate.
For 2020, the conference will be offering main panels, keynote presentations, lightning talks, and a ceremony to announce the winners of Cláudio Weber Abramo Data Journalism Award. Coda.Br and its partners will also be offering 150 free yearly subscriptions to the School of Data Brazil membership program, granting free access to all event activities.
Tickets will be available for R$180 (1 year subscription to Escola de Dados membership, which allows access to workshops and the event chat, among other benefits) and R$40 (workshops only). This translates approximately to USD$32 and $7, respectively.
For more information and to register, please visit the Coda.Br website.
The R/Pharma virtual conference this year was held October 13-15th, 2020. R/Pharma focuses on the use of R in the development of pharmaceuticals, covering topics from reproducible research to drug discovery to genomics and beyond.
Over 1,000 people signed up for the 3 day, free event this year!
Designed to be a smaller conference with maximum interaction opportunities, R/Pharma was a free event that allowed keynote speakers in the R world to present their research and findings in ways that allowed for maximum viewer participation.
All presentations are given in ways that showcase using R as a primary tool within the development process for pharmaceuticals.
If you are interested in seeing some of the exciting work showcased at R/Pharma from the R Validation Hub, you can do so below. The R Validation Hub is a cross-industry initiative meant to enable use of R by the bio-pharmaceutical industry in a regulated setting. The presentations Implementing A Risk-based Approach to R Validation by Andy Nicholls and useR! 2020: A Risk-based Assessment for R Package Accuracy by Andy Nicholls and Juliane Manitz are available for viewing. Learn about risk assessment and assessing package accuracy with the R Validation Hub team!
The deadline for submitting proposals is midnight, October 1st, 2020.
The September 2020 ISC Call for Proposals is now open. The R Consortium’s Infrastructure Steering Committee (ISC) solicits progressive, pioneering projects that will benefit and serve the R community and ecosystem at large. The ISC’s goal is to foster innovation and help bring your ideas into tangible realities.
Although there is no set theme for this round of proposals, grant proposals should be focused in scope. If you are currently working on a larger project, consider breaking it into smaller, more manageable subprojects for a given proposal. The ISC encourages you to “Think Big” but create reasonable milestones. The ISC favors grant proposals with meaningful detailed milestones and justifiable grant requests, so please include measurable objectives attached to project milestones, a team roster, and a detailed projection of how grant money would be allocated. Teams with detailed plans and that can point to previous successful projects are most likely to be selected.
To submit a proposal for ISC funding, read the Call for Proposals page and submit a self-contained pdf using the online form.
JS and R, what a clickbait! Come for JS, stay for our posts about Solaris and WinBuilder. 😉 No matter how strongly you believe in JavaScript being the language of the future (see below), you might still gain from using it in your R practice, be it back-end or front-end.
In this blog post, Garrick Aden-Buie and I share a roundup of resources around JavaScript for R package developers.
JavaScript in your R package
Why and how you include JavaScript in your R package?
Bundling JavaScript code
JavaScript’s being so popular these days, you might want to bundle JavaScript code with your package. Bundling instead of porting (i.e. translating to R) JavaScript code might be a huge time gain and less error-prone (your port would be hard to keep up-to-date with the original JavaScript library).
The easiest way to interface JavaScript code from an R package is using the V8 package. From its docs, “A major advantage over the other foreign language interfaces is that V8 requires no compilers, external executables or other run-time dependencies. The entire engine is contained within a 6MB package (2MB zipped) and works on all major platforms.” V8 documentation includes a vignette on how to use JavaScript libraries with V8. Some examples of use include the js package, “A set of utilities for working with JavaScript syntax in R“; jsonld for working with, well, JSON-LD where LD means Linked Data; slugify (not on CRAN) for creating slugs out of strings.
Now, maybe you’re not using JavaScript in your R package at all, but you might want to use it to pimp up your documentation! Here are some examples for inspiration. Of course, they all only work for the HTML documentation, in a PDF you can’t be that creative.
In writexl docs, the infamous Clippy makes an appearance. It triggers a tweet nearly once a week, which might be a way to check people are reading the docs?
In HTML vignettes, you can also use web dependencies. On a pkgdown website, you might encounter some incompatibilities between your, say, HTML widgets, and Boostrap (that powers pkgdown).
Web dependency management
HTML Dependencies
A third, and most common, way in which you as an R package developer might interact with JavaScript is to repackage web dependencies, such as JavaScript and CSS libraries, that enhance HTML documents and Shiny apps! For that, you’ll want to learn about the htmltools package, in particular for its htmlDependency() function.
As Hadley Wickham describes in the Managing JavaScript/CSS dependencies section of Mastering Shiny, an HTML dependency object describes a single JavaScript/CSS library, which often contains one or more JavaScript and/or CSS files and additional assets. As an R package author providing reusable web components for Shiny or R Markdown, in Hadley’s words, you “absolutely should be using HTML dependency objects rather than calling tags$link(), tags$script(), includeCSS(), or includeScript() directly.”
htmlDependency()
There are two main advantages to using htmltools::htmlDependency(). First, HTML dependencies can be included with HTML generated with htmltools, and htmltools will ensure that the dependencies are loaded only once per page, even if multiple components appear on a page. Second, if components from different packages depend on the same JavaScript or CSS library, htmltools can detect and resolve conflicts and load only the most recent version of the same dependency.
Here’s an example from the applause package. This package wraps applause-button, a zero-configuration button for adding applause/claps/kudos to web pages and blog posts. It was also created to demonstrate how to package a web component in an R package using htmltools. For a full walk through of the package development process, see the dev log in the package README.
The HTML dependency for applause-button is provided in the html_dependency_applause() function. htmltools tracks all of the web dependencies being loaded into a document, and conflicts are determined by the name of the dependency where the highest version of a dependency will be loaded. For this reason, it’s important for package authors to use the package name as known on npm or GitHub and to ensure that the version is up to date.
Inside the R package source, the applause button dependencies are stored in inst/applause-button.
The package, src, and script or stylesheet arguments work together to locate the dependency’s resources: htmlDependency() finds the package‘s installation directory (i.e. inst/), then finds the directory specified by src, where the script (.js) and/or stylesheet (.css) files are located. The src argument can be a named vector or a single character of the directory in your package’s inst folder. If src is named, the file element indicates the directory in the inst folder, and the href element indicates the URL to the containing folder on a remote server, like a CDN.
To ship dependencies in your package, copy the dependencies into a sub-directory of inst in your package (but not inst/src or inst/lib, these are reserved directory names1). As long as the dependencies are a reasonable size2, it’s best to include the dependencies in your R package so that an internet connection isn’t strictly required. Users who want to explicitly use the version hosted at a CDN can use shiny::createWebDependency().
Finally, it’s important that the HTML dependency be provided by a function and not stored as a variable in your package namespace. This allows htmltools to correctly locate the dependency’s files once the package is installed on a user’s computer. By convention, the function providing the dependency object is typically prefixed with html_dependency_.
Using an HTML dependency
Functions that provide HTML dependencies like html_dependency_applause() aren’t typically called by package users. Instead, package authors provide UI functions that construct the HTML tags required for the component, and the HTML dependency is attached to this, generally by including the UI and the dependency together in an htmltools::tagList().
Note that package authors can and should attach HTML dependencies to any tags produced by package functions that require the web dependencies shipped by the package. This way, users don’t need to worry about having to manually attach dependencies and htmltools will ensure that the web dependency files are added only once to the output. This way, for instance, to include a button, using the applause package an user only needs to type in e.g. their Hugo blog post3 or Shiny app:
applause::button()
Some web dependencies only need to be included in the output document and don’t require any HTML tags. In these cases, the dependency can appear alone in the htmltools::tagList(), as in this example from xaringanExtra::use_webcam(). The names of these types of functions commonly include the use_ prefix.
How do you test JS code for your package, and how do you test your package that helps managing JS dependencies? We’ll simply offer some food for thought here. If you bundle or help bundling an existing JS library, be careful to choose dependencies as you would with R packages. Check the reputation and health of that library (is it tested?). If you are packaging your own JS code, also make sure you use best practice for JS development. 😉 Lastly, if you want to check how using your package works in a Shiny app, e.g. how does that applause button turn out, you might find interesting ideas in the book “Engineering Production-Grade Shiny Apps” by Colin Fay, Sébastien Rochette, Vincent Guyader and Cervan Girard, in particular the quote “instead of deliberately clicking on the application interface, you let a program do it for you”.
Learning and showing JavaScript from R
Now, what if you want to learn JavaScript? Besides the resources that one would recommend to any JS learner, there are interesting ones just for you as R user!
Learning materials
The resources for learning we found are mostly related to Shiny, but might be relevant anyway.
As an R user, you might really appreciate literate R programming. You’re lucky, you can actually use JavaScript in R Markdown.
At a basic level, knitr includes a JavaScript chunk engine that writes the code in JavaScript chunks marked with ```{js} into a <script> tag in the HTML document. The JS code is then rendered in the browser when the reader opens the output document!
Now, what about executing JS code at compile time i.e. when knitting? For that the experimental bubble package provides a knitr engines that uses Node to run JavaScript chunks and insert the results in the rendered output.
The js4shiny package blends of the above approaches in html_document_js(), an R Markdown output for literate JavaScript programming. In this case, JavaScript chunks are run in the reader’s browser and console outputs and results are written into output chunks in the page, mimicking R Markdown’s R chunks.
Different problem, using JS libraries in Rmd documents
More as a side-note let us mention the htmlwidgets package for adding elements such as leaflet maps to your HTML documents and Shiny apps.
Playground
When learning a new language, using a playground is great. Did you know that the js4shiny package provides a JS playground you can use from RStudio? Less new things at once if you already use RStudio, so more confidence for learning!
And if you’d rather stick to the command line, bubble can launch a Node terminal where you can interactively run JavaScript, just like the R console.
R from JavaScript?
Before we jump to the conclusion, let us mention a few ways to go the other way round, calling R from JavaScript…
In this post we went over some resources useful to R package developers looking to use JavaScript code in the backend or docs of their packages, or to help others use JavaScript dependencies. Do not hesitate to share more links or experience in the comments below!